Learning Friction at Inference Speed
I am a year late to the process of resolving issues with vibe coded personal software with an “Accept All” mentality. This has worked remarkably well if I think only from the perspective of getting to usable working software prototypes, but has simultaneously induced a dull headache whose source I am still trying to localise. I’ve previously felt similar pains during prolonged learning activities — manually massaging equations on paper; handcrafting/debugging code; and re-designing parts of code — but I would also say those have informed deeper understanding of concepts; the agentic version of this ache has yet to bring obvious understanding to light. So, while one can ship many personally usable things and also scale them for others’ utility at inference-speed, what hasn’t shipped at that speed is an intimate understanding of what lies under the hood. On account of this, sometime in late March, I decided it was time to sober up from this deep intelligence inebriation and re-scope how I worked with coding agents.
Learning speed is inversely proportional to deep understanding, and deep understanding comes from having some learning friction. Agentic chats feel like teleportation; issues are resolved before I can wrap my head around what happened where, but I find myself approximately where I wanted to be. To go beyond vaguely appreciating the need for learning frictions, I am now figuring out which frictions are worth retaining. Classical approaches, like reading or writing notes for myself, serve as personal distillation activities that preserve desirable learning friction; disseminating my learnings about agentic coding to others1 is another useful distillation, but requires having opportunities for and overcoming the fear of public speaking. Making use of agents to accelerate generating associated elements for self-learning is detrimental; outsourcing my capacity of translating thoughts into words to any other entity, agent or human, is a disservice to myself.
When I read about people clamouring for newer IDEs, I think the problem they are thinking about is, “How do I introduce agentic learning frictions?” Newer ways of reading code are waiting to be uncovered and could be one way to solve part of the problem. There might also be better ways to use existing tools and LLMs. And so I am trying to find agentic versions of learning friction that retain the benefits of speed without compromising my long-term understanding.
Below, I demonstrate some things I am having these agents build that feel like solutions to this problem. At this moment, they feel like the kinds of things that are helping me understand how to work with them: by reading and annotating their code using pre-LLM tools — like Obsidian and static websites — in my pipeline.
Botference: Agentic Review Loops
The first builds on the well-trodden idea of using agentic review loops — one agent reviews another’s work — that is sometimes fruitful, but more often entertaining. I suspect such loops are likely more token-efficient when reviewing implemented code, but I prefer now to also use them in reviewing plans prior to coding.
Previously, I used a manual approach of copypasta-ing Claude’s plans to Codex (and vice versa); this helped me see Codex as the more detail-oriented engineer with a bias towards testing everything but also reading code deeply alongside Claude’s bias to prototyping with less thorough codebase exploration. The qualitative gains felt like accelerations to me, but the overhead of flipping from one terminal induced migraines. So, I got the two to scheme on Botference, a Terminal User Interface (TUI) that hosts both models in the same terminal session. The general premise was to collaboratively ideate in a main chatroom with the three of us — this is called Council. However, if we get to a point where changes need to be made to an unfamiliar-to-me codebase2 or they hold differing opinions on some matter, I send them into a private room — called a Caucus — where I can’t chat. The two hash things out in Caucus in about tenish messages to eventually return to the Council to inform me if they have converged on a path forward (or not) and which of them will lead plan authoring; the other agent automatically becomes the reviewer of this plan over as many rounds as I need. Botference’s interface is below:
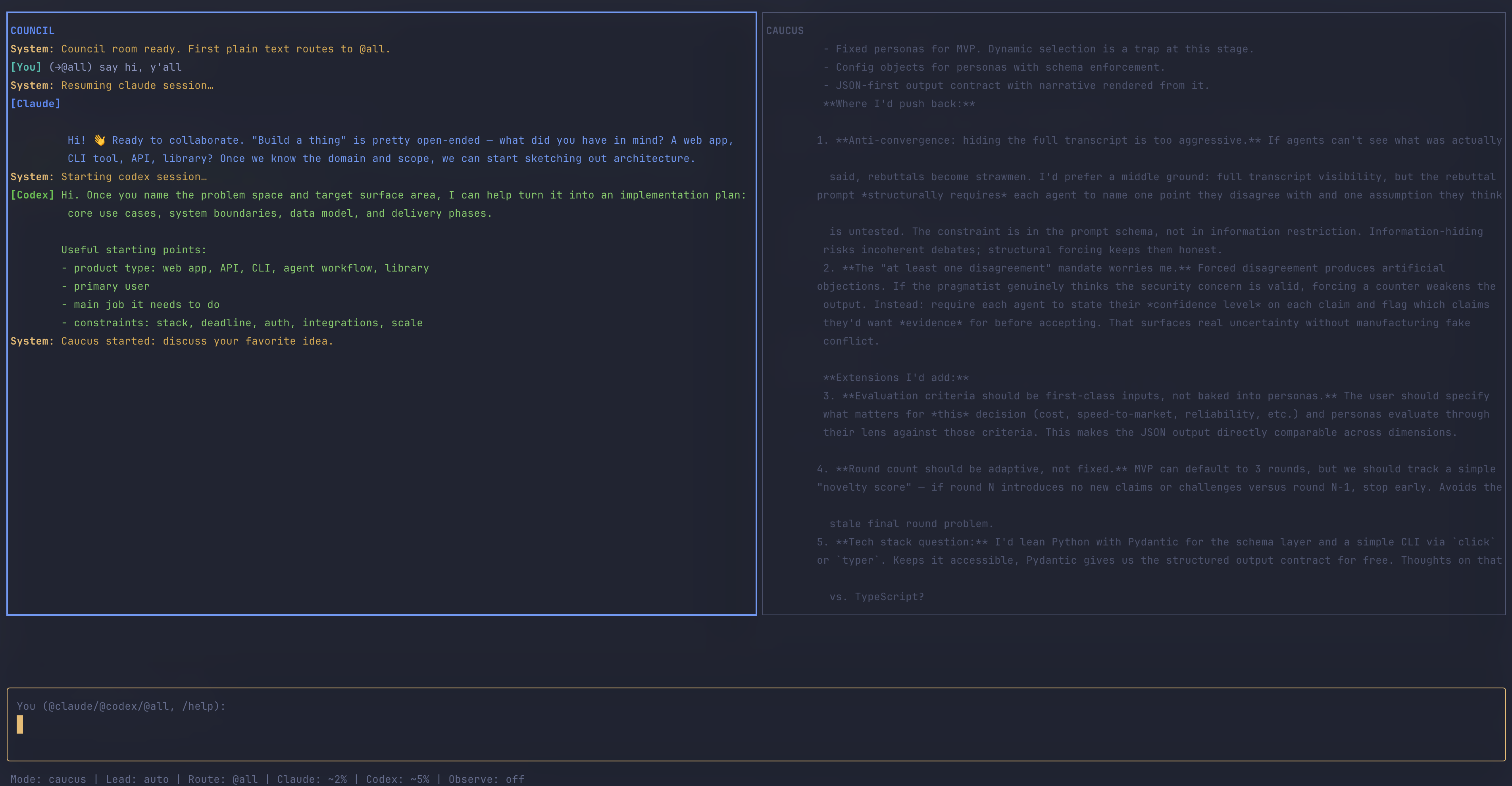
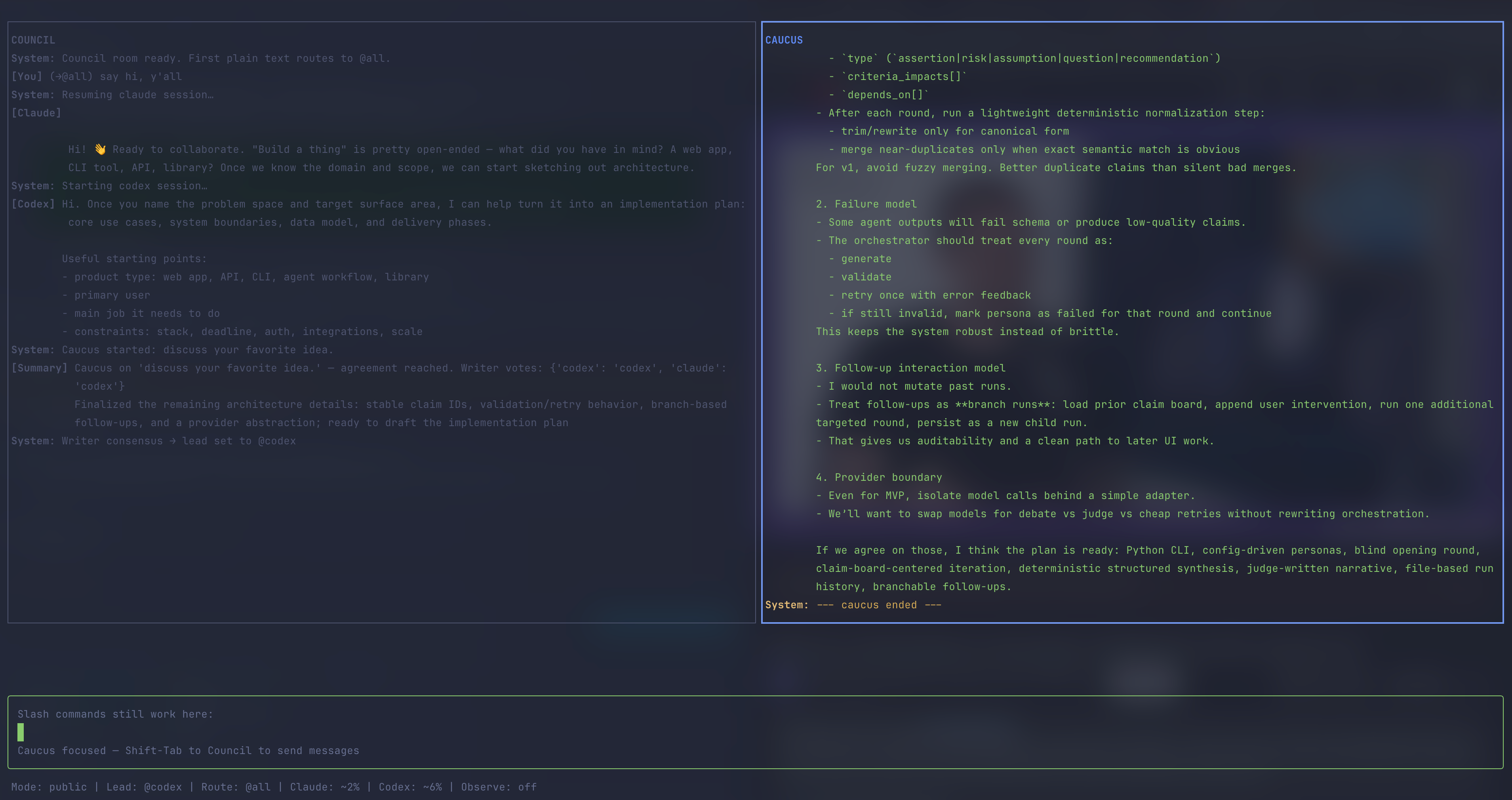
Though it is difficult to prove whether this is a better way to plan out code than the copypasta approach, I have found it cognitively far more manageable to read a serialised chat between two agents than reading their thoughts in two terminal windows placed side-by-side; this has felt like reading two pages of a book at the same time. The doubling in plan files was cumbersome to read so I quickly defaulted to letting agents decide rather than steering them towards my decisions; this combination of multi-terminal swapping and multi-file spawning was one cause of a headache that is less frequent now — if we ignore the sheer volume of text still being generated inside Botference.
The main artifact from a Botference chat in plan mode is an implementation-plan.md (though additional files can be requested from the agents within the Botference workspace). I usually implement that plan from a second terminal with botference build -p. The -p flag means headless: Botference spawns custom coding agents and gives them tools either through a direct API call or, when I am using my Claude Max subscription rather than an Anthropic API key, through a scoped MCP server. Dropping -p launches a regular interactive Claude Code session instead.
Using two terminals — one to plan, another to build — prevents the build phase from gobbling up the planning chat’s context window, and lets me steer a build more deliberately than I can in a Claude Code or Codex session where plan-and-build share a single chat. This is especially useful when a plan contains human-review gates. Those gates are planned into Botference to force me to navigate the codebase — a deliberate, albeit marginal, learning friction that helps me understand how the code is laid out even if I am not principally writing it.
The next section discusses a feature made with Botference that helps me better read and agentically annotate a codebase for my understanding.
Codetalk: Making Agent Code Legible to Myself
I have derived most use from Botference in my Obsidian vault, which I consider a brownfield codebase — it has years of accumulated notes that inform generation of LLM Knowledge Bases, but is also where this site’s contents are written and then pushed to Github for deployment. In other words, Obsidian is indispensable to my workflow and, fortunately, one I love to edit in. But I seldom use Markdown to explain code-snippets in my blog as I find them an inappropriate format for explaining large chunks of code.
In this agentic era, there is way more code being written and forgotten about than ever before; this means code is either unimportant to read or super-important to read. For this latter case, I had Botference engineer Codetalk as a new way for me to read and annotate code-specific files from Obsidian that I then review from a local build of my site.
Codetalk allows me to drop a spotlight on specific lines of code and make annotations beside it; the rest of the lines are dimmed while an annotation is in view. When a section involves multiple files, they appear as tabs you can switch between. The goal is not to annotate every line, but to trace a path through the parts that matter for a particular discussion. This possibly makes for — or can be further tweaked to offer — a more informative and less linear code-reading experience for other humans than, for example, something like Jupyter BooksI love them nonetheless. allows.
I have introduced it into my workflow in a bid to better review and understand agent-written code. Sometimes I am writing the annotations, at other times the annotations are agentic; I often ask agents to spotlight certain behaviours of a codebase and which files are integral to them so they add annotations for me to read on my browser. This practice becomes not just about reading every line, but understanding which are the right lines to spotlight; this might inform later refactors of a large codebase, or will benefit some other researcher or agent in grokking the core idea in a codebase that is not merely scaffolding.
For a blog post such as this one, the editorial choice of which lines to spotlight and explain remains mine. As a demonstration, Codetalk is used to present three aspects of Botference: the first explores its architecture; the second is a multi-tab control loop that moves between botference.sh and detect.sh; and the third is a multi-tab exploration of how Botference’s build agents get their tools through exec.sh, fallback_agent_mcp.py, and __init__.py.
Botference Architecture
The file tree below follows the execution path of a single Botference run, from the moment you type botference plan to the final archived output once you have completed building what was in the plan. Each section maps to a phase of the system’s lifecycle and so is not a raw ls on the contents of Botference. Scroll through the files in the tabs below to get a sense of how Codetalks works in its current iteration.
Everything starts with the botference bash script in the terminal; botference plan starts a chat with the models and botference build -p implements the plan. The shell script reads context-budgets.json to know which model and token budget an agent uses. Auth is resolved later: API keys in .env enable direct API calls, while headless Anthropic builds without an API key fall back to the Claude OAuth subscription path.
Under lib/ are shell scripts that set up the environment via config.sh and provide additional scaffolding for much of the work done during build phase (e.g., detect.sh determines which agent must be used; exec.sh contains build helpers for model resolution, prompt construction, and MCP setup; monitor.sh watches token budgets and triggers new sessions so that tasks are always completed by agents in the supposed smart zone).
The .claude/agents/ directory is basically how Claude Code recognises user-defined agents; these are more specifically tailored to research paper writing tasks so when I run botference research-plan, both Claude and Codex know about the agents before a single chat message is sent. agent-base.md defines the shared protocol that all agents inherit — checkpoint discipline, yield behaviour, incremental commits.
There is a (mostly untested in Botference) Orchestrator agent in orchestrator.md to decide which agents to dispatch and in what order, used in the orchestrated architecture mode for non-serialised builds.
work/ is the live state of the current thread of work. At first, it contains the outputs of a planning discussion: implementation-plan.md, which states the sequence of tasks and assigned agents, and checkpoint.md, which tracks the next build task. Once build begins, checkpoint.md also accumulates handoff notes from the outgoing agent to the incoming one. inbox.md lets me leave additional notes for the next agent without interrupting the loop.
Under tools/, Botference defines a shared tool registry. __init__.py maps each agent type to the tools it is allowed to use. The individual files are tool modules. core.py contains the basic local primitives — reading and writing files, running shell commands, and committing or pushing with git. I put this in because I wanted to limit capabilities of build agents, which I discussed in RalPhD.
Some research-specific modules are highlighted here as examples of how the same registry can grow: claims.py can check manuscript claims against evidence; pdf.py can inspect PDFs or render pages; download.py downloads PDFs of papers where available; and latex.py can compile LaTeX or build citation trackers. The important architectural point is not the full list; it is that agents get a scoped subset of these capabilities. A non-research module, search.py, handles file listing and code search; it shows that the registry is not only for research-paper tooling.
The Python core in core/ runs the models: botference.py manages the orchestration loop, botference_agent.py bridges agent markdown specs to direct Anthropic/OpenAI API calls, and providers.py abstracts the model APIs so the rest of the system doesn’t care whether it’s talking to Anthropic or OpenAI.
There are two ways Botference exposes tools to an agent during build. In the direct API path, botference_agent.py passes tool schemas from tools/__init__.py to the model provider and executes returned tool calls locally. In the Claude CLI/subscription fallback, fallback_agent_mcp.py wraps the same registry as an MCP stdio server.
This is not an elegant or ideal architecture necessarily, but is one approach to steering the build agents to evaluate or reconsider their work.
The control loop
Botference has two planning modes — plan for general work has no system prompt, and research-plan loads high-level details about built-in academic research agents — and two build paths: headless (-p) or interactive. botference.sh is the shared entry point for all four; detect.sh only enters once build mode takes over, reading the plan/checkpoint state to decide which agent runs to complete the next unchecked task. I co-annotated the architecture.txt and botference.sh with Botference, but the remaining files of this post were annotated by agents as I peppered them with questions. Note that these annotations don’t suggest that the code was assessed for quality/concision but do give me a stronger sense of what is happening where in the code.
(shared entry) parse_loop_args reads the command-line arguments and sets LOOP_MODE — this is the variable that determines whether Botference runs in plan, research-plan, build, or init mode.
(plan / research-plan) The interactive-only guard. plan and research-plan reject the -p (pipe/headless) flag. You cannot plan headlessly because the whole point of these modes is human steering.
(plan / research-plan) The plan mode entry. If LOOP_MODE is plan or research-plan, CURRENT_AGENT defaults to “plan”. The script resolves models for both Claude and Codex — Claude’s model comes from resolve_model("plan"), while Codex defaults to gpt-5.4.
(research-plan only) The research-plan fork. If the mode is research-plan, the script loads the plan.md agent file as a system prompt — this gives both models awareness of the research agents (scout, deep-reader, critic, etc.) before the session starts. The else branch sets PLAN_SYSTEM="", so no system prompt is loaded in plan mode.
(plan / research-plan) The Ink TUI council launch. node ink-ui/dist/bin.js starts the React/Ink terminal UI with both models. The system prompt and task are written to temp files to avoid shell escaping issues.
(plan / research-plan) The Python fallback. If the Ink UI is not available, python3 core/botference.py launches the same council session with the same model flags. Both backends produce the same output artifact: an implementation-plan.md.
(handoff: plan ends, build begins) Plan mode is one-shot. After the session: “Planning session complete. Run ‘build’ to start executing.” Build mode picks up from here — the iteration counter increments, and the loop begins detecting agents from the checkpoint. The detection logic is annotated in the detect.sh file tab, but there are more botference.sh annotations below.
(headless build: API vs MCP choice) Auth detection for headless builds. If the model is Anthropic but no API key is found, the script assumes it should use the Claude CLI/OAuth subscription path instead of the direct API path. It sets USE_CLAUDE_FALLBACK=true and builds the system prompt. This is where the MCP path gets activated. The larger dispatch logic is supported by three predicates defined in exec.sh — is_openai_model, has_anthropic_api_key, and is_anthropic_model — which are covered in the agent tool surface section below.
(headless build: MCP fallback) The MCP fallback command. The prompt is piped into the Claude CLI with --tools "" (blanking native tools) and --mcp-config pointing to a generated config that starts fallback_agent_mcp.py. The agent gets exactly the tools its registry permits, nothing more. The MCP server itself is annotated under fallback_agent_mcp.py below.
(headless build: direct API) The direct API command. When an API key is available, the prompt goes through botference_agent.py which calls the Anthropic/OpenAI API directly with the shared tool registry.
(interactive build) What happens when you drop -p. Without the headless flag, Botference launches an interactive claude session with --append-system-prompt. No MCP, no tool blanking — the human is in the loop and can steer directly.
extract_agent_from_task_block grabs the last bold word from a task in implementation-plan.md. A line like - [ ] 1.2 Write the auth module — **coder** yields coder. This single string is the join key across all four layers: prompt, model, tools, agent file.
The detection flow. detect_agent_from_checkpoint reads the “Next Task” from the checkpoint.md. If that field contains end-of-run markers or prose instead of a real task line, it falls through to the first unchecked task in implementation-plan.md’.
Validation. The extracted agent name is passed to resolve_agent_path, which checks three locations in precedence order: project-local first, then .claude/agents/ in the working directory, then the framework’s own agents directory. The three-tier order matters when Botference runs in a brownfield codebase that has its own pre-defined agents. Project-local comes first because Botference lets me add agents beyond its built-in ones; the downside is potential name-clashes, so I typically add those additions as explicit tasks in the plan. If no file matches, the agent is rejected.
The agent tool surface
These files are the machinery that botference.sh calls into when a build agent needs to run:
-
exec.shresolves the model and constructs the prompt and MCP config. -
fallback_agent_mcp.pyadapts the tool registry for CLI execution; it is a model-agnostic bridge so nothing in this file references Claude or Codex — it takes an agent name, builds a tool set, and speaks MCP over stdio. -
__init__.pyis the shared tool registry. This mapping feeds both the direct API runner and the MCP fallback.
Together, these files implement the coding-agent pattern discussed in RalPhD: each agent is bound to a role-specific tool set rather than the full kit.
resolve_model — per-agent model selection. Checks ANTHROPIC_MODEL as a global override first, then looks up per-agent config in context-budgets.json. This means different agents can run on different models within the same build loop.
build_claude_system_prompt resolves the agent’s markdown file from one of three locations: project-local, .claude/agents/, or the framework. This mirrors the same project-first precedence used elsewhere in Botference.
After the path and file-layout preambles are emitted, the resolved agent markdown is appended to the prompt. Tools are not embedded in the prompt — they come separately through the shared registry3.
The punchline of build_mcp_config: a heredoc that writes a temporary JSON config telling the Claude CLI to spawn fallback_agent_mcp.py as an MCP stdio server. botference.sh only passes --mcp-config; the concrete Python server path is generated here at runtime and cleaned up after.
build_server creates an MCP server scoped to the given agent. It calls get_tools_for_agent to determine which tools this agent is allowed, then filters out server-side tools like web_search — those are handled by the model natively, not by local Python handlers.
The MCP server’s read side. list_tools returns only the scoped tool set for the current agent.
The MCP server’s execution side. call_tool executes a requested tool and returns the result using the same execute_tool dispatcher that the direct API path uses.
_ESSENTIALS and SERVER_TOOLS. Every agent gets the essentials (read_file, write_file, bash, git_commit, git_push, list_files, code_search). SERVER_TOOLS defines capabilities like web_search that the model handles natively — the MCP wrapper skips these.
AGENT_TOOLS — the per-agent scoping. scout gets web search, citation, and PDF tools; critic gets language checks, figure checks, and claim verification; coder gets just the essentials plus GitHub. Line 64: plan mode uses the Claude CLI directly, so it does not need this build-agent registry.
End
The Codetalk you just scrolled through is itself a Botference artifact — planned in its Council and Caucus, later built via build -p (with some minor touch-ups from within Claude Code) and then annotated from within Obsidian. The annotations are not exhaustive. I did not spotlight every function or trace every edge case. I chose specific lines — the mode guard, the bold-word convention, the MCP heredoc — because those are where the architectural ideas live.
This is the practice I want to carry forward when agents write code — especially where no visual or interactive testing is possible. I asked the agents to annotate their output here, and then exercised the editorial judgment of further titrating because they wanted to highlight all of the code and write verbose explanations.
AI-human teams mightI am tempted to use “will”, but I want to be measured. end up doing amazing things; for that we will need to find better ways to work together. Maybe things like Botference will help; maybe they will hinder. But introduction of learning frictions will matter once agent-written code accelerates us toward new potentialities. If you are curious to try Botference, you can do so here.
-
I have: given a talk to engineers at Github Next on engineering experimental harnesses towards hallucination-free PhD-level research paper-writing, and run internal workshops for academics/students on agentic tools in physical sciences and engineering. ↩
-
Not if, but when because it is a matter of time before they surpass my understanding by using coding jargon I am unfamiliar with or decide on what might be a better implementation architecture for an idea. ↩
-
The asymmetry is interesting: Claude agents get system-level tool boundaries via
--tools ""plus MCP scoping, while Codex agents get the honor system —codex --full-autowith no granular tool restriction. An open issue has been requesting per-tool control since October 2025. ↩