RalPhD and The Autonomous Paper
After reading Maggie Appleton’s excellently illustrated blog post, I began building a Gas Town-inspired multi-agent system that could autonomously complete PhD-level research goals1. One such goal is writing a research paper targeting a specific journal.
One of my system’s early outputs spans 94 pages and surveys soft robotics for space applications for submission to Progress in Aerospace Sciences; it was wholly authored by a team of 20+ agentsI use the word agent quite loosely here but will clarify this later in the essay. in roughly 8 hoursThis is worthy of a blog post on its own but on a later date, perhaps. from a 2-minute voice prompt without any further steering. The agents run as Github Actions jobs so all work is completed inside the repository; this allows overnight jobs and gives me a break from screensOver Christmas break, a Cloudflare tunnel to my laptop (when on) allowed triggering work while not near it. while being cost-effectiveIt is within Github Actions’ free limits with the downside of higher latency than a setup involving a virtual machine or sandbox. A quick review showed hallucinated reference entries; this paper is unworthy of submission to a scientific journal for a variety of reasons, but I have submitted it to the new Journal of AI Generated Papers. While I confirmed the hallucinated referencesI wasn’t surprised at these hallucinations; a vibe-coded system that relies only on prompts can only be so effective., I suspect there are also hallucinated claims — I have not closely checked for these. I also tested this system to generate a literature review to identify a specific gap in weather modeling for Rich Pauloo, a dear friend interested in validating NVIDIA’s Earth-2 CorrDiff on a sub-regional scale. His task input to the system was a 300-word WhatsApp message that you can read here and the AI-generated outputs are in a separate branch here.
Despite the errors in the outputs, Rich and I felt that such setups can definitely be steered towards accuracy by engineering better workflows and tooling around large language models (LLMs). Looking at the longer paper, my speculation is stronger still: that such a vibe-coded system comprising LLMs could be engineered outside a frontier lab to fully autonomously write hallucination-free papers of serious breadth, depth, length, insight, and rigour. For the purposes of this post, I call this the autonomous paper. LLM scientific writing is already at a quality high enoughIt is certainly higher than mine was as a new PhD student in 2009. for acceptance into a peer-reviewed journal, but LLMs remain weak at claim veracity and novel idea discovery.
This early effort on autonomous papers still feels like a fun experiment to work on as a means to better use modern AI tooling. It now underpins my attempt at RalPhD, a system aimed at hallucination-free autonomous research papers. The engine of this system is the Ralph loop, which I discuss next. In this post, I present some of the key things I learned while building the RalPhD system, which is yet to be battle-tested; this setup is quite different from the earlier system described above. So, I wouldn’t recommend anyone use it as yet — or use at your own risk as it’s likely riddled with bugs. But I needed to write this down to just clear my thoughts having spent far too much time on Claude Code than is reasonable or healthyWriting this piece has been refreshing and feels like it has exercised muscles that I haven’t used since November..
The Ralph Loop
To improve on my first attempts at autonomous papers, Rich nudged me to study and potentially incorporate the Ralph loop into my systemWhich should explain why the new system is called RalPhD.. Introduced by Geoff Huntley in mid-2025, Ralph remains a hot concept in software engineering circles2: the idea is to have the LLM systematically implement a sequential plan inside a while loop. The LLM works, uninterrupted, until all tasks in the plan are checked off; the bash script to achieve this is effective and also deceptively simple:
while true; do
cat build-prompt.md | claude --dangerously-skip-permissions
done
When I reviewed the innards of the first vibe-coded autonomous paper system, I found a similar-looking while loop; a closer examination revealed that a while loop does not a Ralph loop make. So, what does?
Well, here is what my system was doing:
while true; do
cat implementation-plan.md | claude --dangerously-skip-permissions
done
If you look closely at the markdown file that is being piped into Claude, you will notice that my approach was looping Claude through an entire plan (i.e., implementation-plan.md) whereas Huntley passes a meta-prompt (i.e., build-prompt.md) that asks Claude to specifically complete only one task from the plan per iteration of the loop. As you can see in the image below from his Ralph loop demo3, he specifically prompts the agent to study the implementation plan and pick the most important thing to do and follows it with IMPORTANT: update the implementation plan when the task is done.All-caps ensures Claude pays special attention to these bits.. My orchestration system’s implementation-plan.md lacks this higher-level constraint so Claude would plow through the plan in the same context window, which was prone to automatic compaction4. This is certainly one of the causes for hallucinations. I have since improved my first implementation to match Huntley’s task-level prompt.
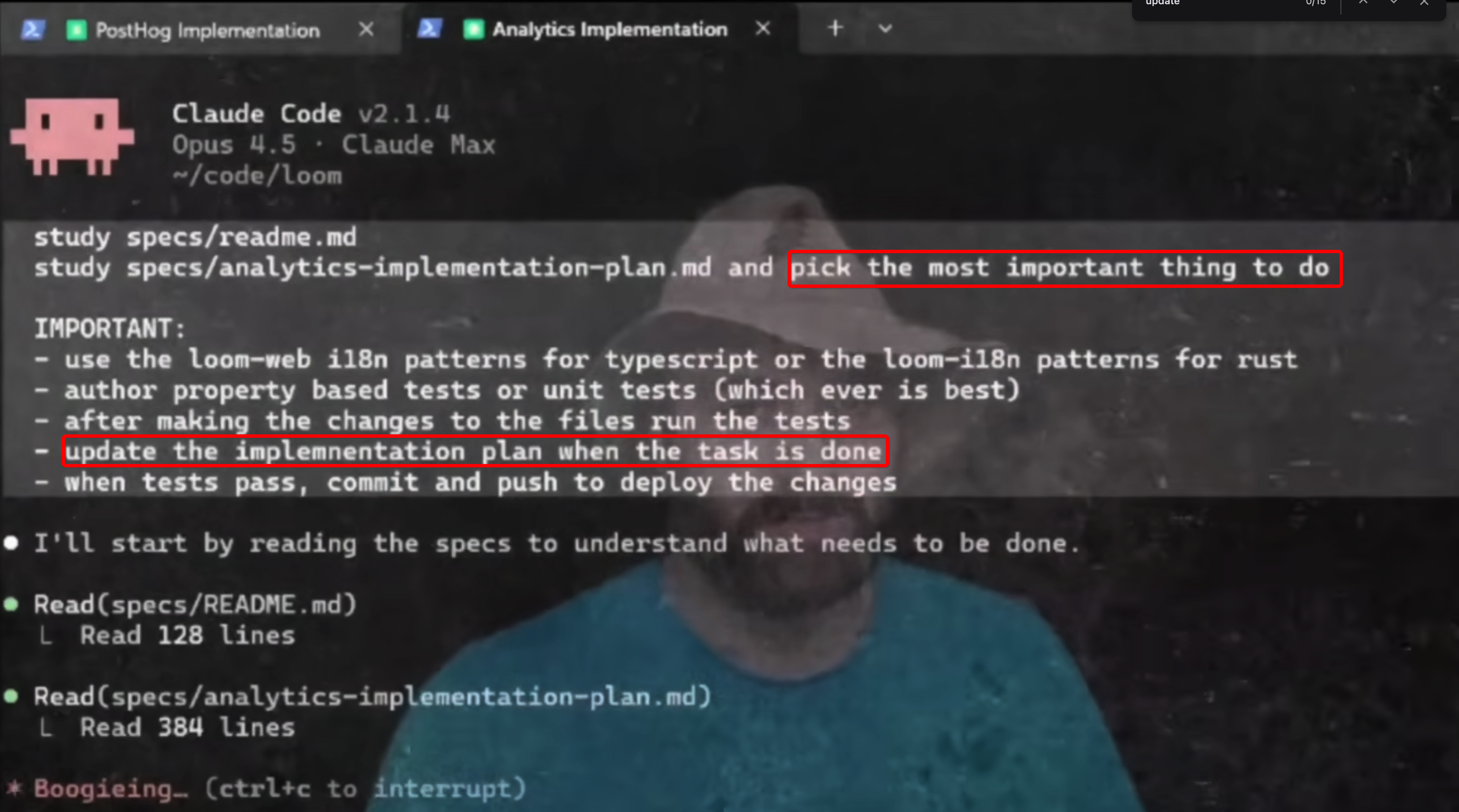
While an LLM’s prompt-following is not always reliable, Huntley’s “how to Ralph” provided testable guardrails to my first implementation; so far, every task has started in a fresh context window and I noticed improvements, i.e., fewer hallucinated references.
That said, I was suspicious that great results would be achieved based on purely prompting better. So, I incorporated linters into my system that offer a more deterministic pipeline of removing hallucinated citations.
I also refined the Ralph loop by better managing how long Claude works on a specific task inside the while loop. The general idea is based on the observation that Claude’s performance drops as chats get longer.
Now, I have a separate bash script monitoring if the chat has gone on for too long by monitoring the context window of an LLM (more in the next sections). At some threshold value, this monitor creates a yield file that then triggers Claude to wrap-up its current subtask, make a commit, update a checkpoint.md stating the next session’s subtask. Note that I do not ask the agent to update the implementation-plan.md at yield time; as the task remains unchecked in the main implementation-plan.md, the new session’s Claude re-situates itself in the unchecked task and the checkpoint.md has the needed granularity of the sub-task. These ideas underpin RalPhD as well.
Yes, after nearly two months of Claude Code, I was reading code again.
Of Coding Agents in Ralph Loops and Harnesses
The ideas I’m about to present here seem straight-forward and common sense in retrospect, but the density of useful information on AI coding is concentrated in podcasts and Zoom recordingsAll hail oral culture, I guess?. Consequently, the knowledge feels less diffuse than it actually might be. But this modality also makes it feel more ephemeral and less enduring in my memory. Add to these my bad habit of dumping links into Claude for summarisation and general Claude Code-fatigue is a definite recipe for poor long-term information retention; coherent gestalts are essential in fast-moving fields like AI5.
It was in one of these AI builder community call recordings that I learned of the smart and dumb zones in an LLM’s context window. It is purported that LLMs are in the smart zone between 80k to 128k tokens — between 40% and 64% of the earlier Opus’s 200k token context windowDex is still holding onto the 100k tokens with Opus 4.6’s new 1M window. — so less is more. Loading too many MCPs, for example, fills the context window enough to put the LLM in the dumb zone — this can happen even before a single user message is sent.
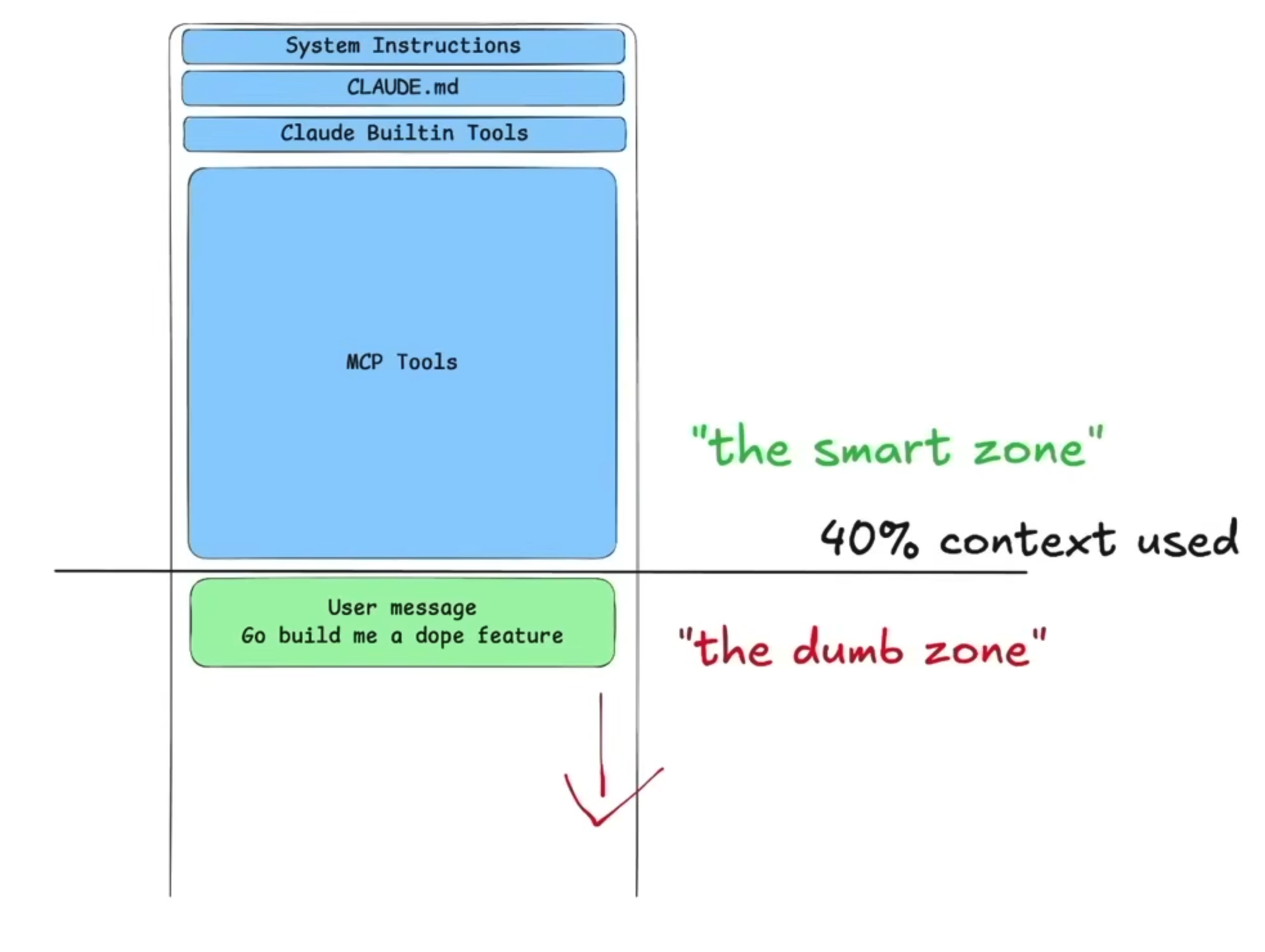
Being more judicious with each of the items in blue can better ensure that your agent operates in the “smart zone” for longer, as shown in the below schematic.
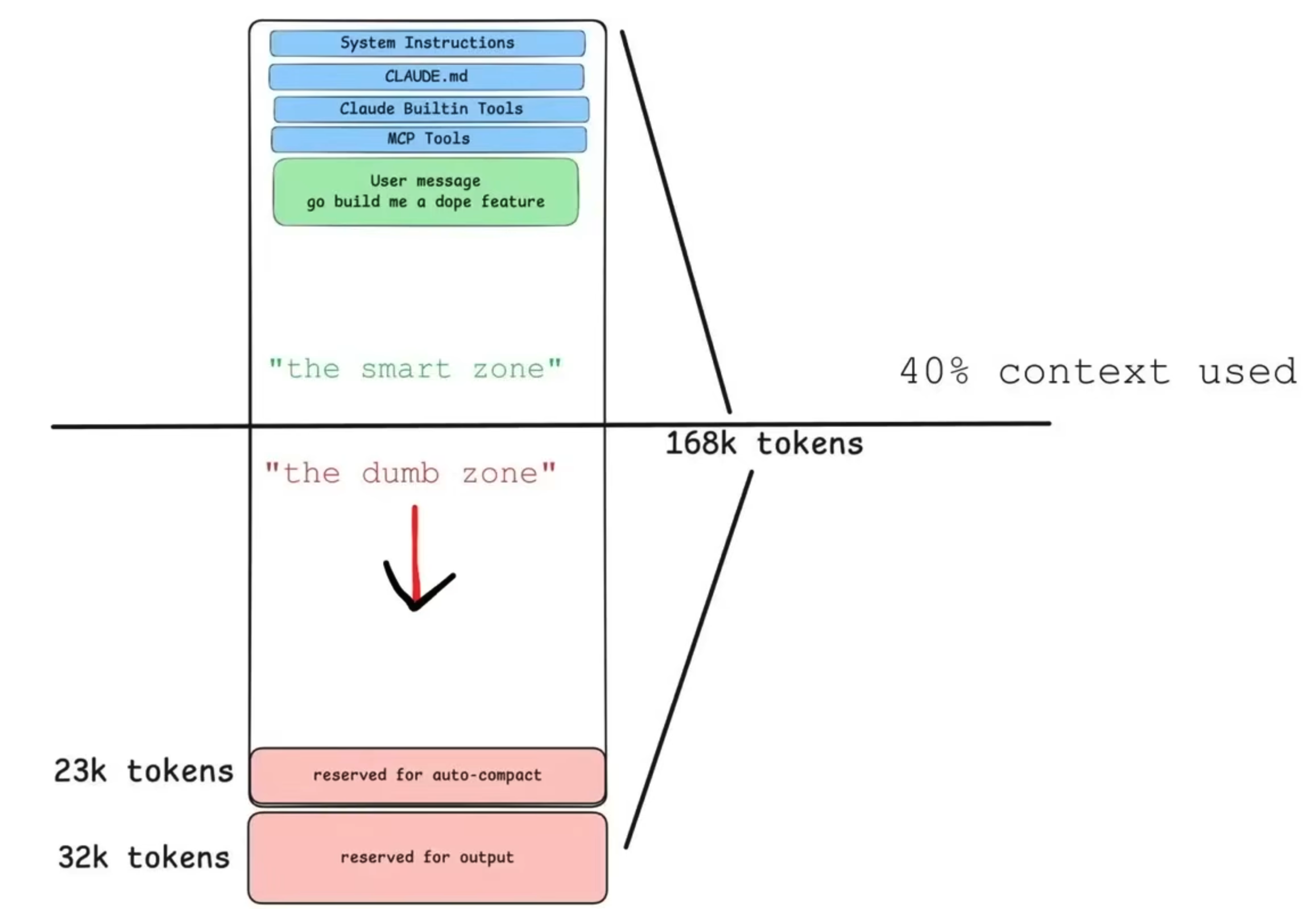
Ralphing had helped resolve issues (potentially) linked to compaction and context rot. I wondered what other ways there might be of more effectively using context and also making LLM behaviours more deterministic. It was around this time that I sat more deeply with Huntley’s piece on coding agents; I realised that his ideas integrated nicely with the notion of the smart and dumb zones6.
Huntley’s explanationEven if others called it that before Huntley, this was my first introduction to a specific definition. of a coding agent is that it’s a program to restrain the agentic urge of an LLM to only use7 a specific set of tools to build software to specifications (or specs). One can program an agent’s tool use capabilities in a Python script by only accessing the reasoning engine and giving this engine only those tools essential for its role in the plan.
For example, consider two agents in the RalPhD setup: the deep reader and scout. The former should only do two things: read a paper or article or blog post that is stored in the project’s library and write notes on it. If it feels the need to read something else not in this collection, it shouldn’t be allowed to go out and find it on its own — this will fill up its context window. Instead, it should delegate that task to the scout, which is much like a research librarian; it shouldn’t be taking notes about a paper or reading its contents deeply, but should find the relevant literature and collect interesting papers by reading abstracts8. To ensure they operate in the smart zone, I can program them per Huntley’s idea to use specific tools in completing actions. To this end, I have a Python script for such agents, say agent.py; pseudocode for the aforementioned scout and a deep reader are shown below:
# scout's inner loop if --agent "scout":
while True:
response = claude.complete(task)
if response.wants_tool:
result = web_search(response.query) # the only discovery tool it has
task = result
if yield_file_exists():
break
# output: scored_papers.md — NOT analysis notes
# deep-reader's inner loop --agent "deep-reader":
while True:
response = claude.complete(task)
if response.wants_tool:
result = read_pdf(response.pages) # the only input tool it has
task = result
if yield_file_exists():
break
# output: notes.md — NOT the next paper to read
In each case, you can see claude; this is the reasoning engine alone, not the hyper-tooled ferret you get in Claude Code with access to each and every tool it desires. In simplified terms, the scout’s main discovery tool is web_search, whereas the deep reader’s main input tools are for reading PDFs and writing notes. This while loop — also called the inner loop — is where each agent repeatedly uses its allocated set of tools.
Conceptually, each agent is then invoked inside a Ralph loop — this is the outer loop — and one implementation path in RalPhD dispatches that agent through a Python runner, as shown below:
while true; do
cat build-prompt.md | python3 agent.py --agent "$AGENT"
done
You will notice that the revised Ralph loop runs the agent via a Python script (python3 agent.py) whereas the erstwhile loop passed a build-prompt.md to claude. So, we now have a tool-delimited coding agentCodex wants me to call this an agent runner to be more precise as it is the script that dispatches the coding agent.; this ought to lead to more deterministic behaviours in each agent. In practice, RalPhD also supports another headless runtime path for Claude subscription/OAuth users, where Claude Code runs the model loop while RalPhD exposes the same per-agent tool boundaries through an MCP layer, conceptually like so:
while true; do
cat build-prompt.md | claude -p --mcp-config <agent-mcp-config>
done
In the broader RalPhD setup, the scout gets web_search, citation_lookup, and citation_download; the deep-reader gets read_file, write_file, and some tools for manipulating PDFs. I am simplifying here: in practice each agent also has a small set of supporting tools for file I/O, checkpointing, and commits. There are a slew of other agents like coder, paper-writer, and others; I’m hoping to battle-test this multi-agent implementation later this week. Strictly speaking, scout, deep-reader, and paper-writer are agent prompts. The coding agent emerges when you run RalPhD, which binds the specified agent’s prompt to a model and pre-defined tools allocated to that agent type.
Hopefully, this clarifies a bit of what I am working towards with RalPhD; or, at least, how I intend for it to work in the near term towards becoming an autonomous paper authoring system.
Going over these foundational ideas in agentic loops and content management is a part of agentic engineering; it has been beneficial at an implementation level, but it has also clarified terminology to me. For example, not all LLMs should be seen as agentic9. My spinterpretationspin+interpretation of this is that agentic LLMs are the subset of all LLMs with the distinguishing property that they are capable of using tools to script programs and, therefore, effect change in your codebaseEither on your machine, virtual machine, or a repository on Github/elsewhere.. So, by extension, coding agents are the subset of agentic LLMs with programmatically restricted tool-calling capabilities of agentic LLMs.

Another common and confusing terminology is a harness. One definition is below; from Huntley’s site (which I need to find the link to).

This feels like a product centric set of analogues but feels to me a very powerful concept; RalPhD is, in fact, a harness because it turns an agentic LLM into a set of coding agents that will behave the way I want them to.
But that said, if even this way of thinking about coding agents and harnesses fails to land then here’s another version I have found helpful. A coding agent is like a powerful but well-trained dog in a harness; you walk it but it doesn’t walk you and, if you trust it enough, you will even let it walk itselfThe autonomous dog!. An agentic LLM is one step removed from that; it’s like a powerful but poorly-trained dog on a leash; it takes you for a walk and drags you in directions you didn’t mean to go, for example, when it sees a squirrel scamper by. As for an LLM…. well, I don’t have a good analogy so I’ll just say it’s like a fox; you see it once in a while from a distance, but harbour limited desire to get closer to one, even if it looks kinda cute — especially after you’ve had a dog.
Closing Remarks
While Ralph loops feel quite fundamental, I suspect they will become less important in software engineering over time. Eliminating the poor performance of models in the supposed dumb zone is probably already the focus at frontier labs. Once solved, fully autonomous software engineering that is reliable should arrive in the next couple years.
I am certain that an autonomous paper authoring system can be vibe-engineered — and many will build them. I am less sure that widening the smart zone in an LLM’s context window will lead to their independently and autonomously making new discoveries. This will be particularly difficult in data-deficient domains, unlike much of the life sciences. But AI-augmented human researchers will make discoveries faster; better explore the breadth of the design space of any problems; and also find connections in literature by better steering synthesis agents in a multi-agent team. In that setting, robust harnesses still matter. Ralph’s principles may remain useful in research not only for managing model context, but also for managing human context by limiting the volume of AI output a person has to evaluate.
Many will argue that Huntley’s ideas do not translate to research goals as they cannot be easily broken down into small tasks; therefore, it is not like engineering new software. But my position is that a research goal can be broken into better defined questions that then become a series of clearly defined sets of tasks, i.e., each task set can answer each question. My gambit is that planning alongside Claude is very effective for this task definition albeit it requires a certain level of expertise10 and the discomfort of thinking with Claude. Once the plan is set up, we have to trust Claude’s intelligence to iteratively implement the plan or improve it on-the-fly using its reasoning abilities during implementation. This also describes the pathway to autonomous papers, which feels clear as I write this but not necessarily easy.
What I remain uncertain about are the implications of such systems for academic publishing. If papers become easy to generate and institutions continue to incentivise metrics-oriented publication, editors and reviewers may simply be overwhelmed until they too are replaced by AIs. At that point, AIs would be writing scientific outputs largely for other AIs, which feels bleak. The more hopeful possibility is that AI-augmented researchers will use such systems to pull futuristic ideas into the present more rapidly: cooler sci-fi ones like sustainable human exploration of deep space and the subsea, alongside more sensitive ones around reducing suffering at psychological, physiological and ecosystem levels. That vision feels more exciting to me because these systems — even just as high-quality document generators — would then become a means to an end rather than an end in themselves. Aligning oneself with such vectors of progress is more likely to provide longer-term purpose and satisfaction.
My longer-term objective is to use these ideas to make more personally meaningful and tangible progress on building spaceships without, for example, the hallucinations of the above paper. With few funders11 for such work, perhaps a team of AI agents working alongside humans — an agentic research team, if you will — can help drag this idea from the future into the present.
-
As this lacks a singular definition, I define this as the kind of research question that lacks an answer — or, at least, a definitive one. A PhD is awarded for making the question seem worthwhile to have spent time thinking about alongside developing an acceptable set of answers that either resolve the question or lead to even more questions. ↩
-
This is saying something for an idea in AI, where progress is so rapid that anything that lasts a couple months feels Lindy. The Ralph concept is about 9 months at this point. ↩
-
His Lynchian masterpiece is hard to follow in one sitting for non-software engineers but I suspect its production and idea density ranks it as one of the great demos, alongside Engelbart’s. ↩
-
I am no expert on how compaction happens, but my suspicion is that an LLM is likely being used to summarize the work when maximum context is used. So, if a long implementation plan is being executed on, lossy summarization is the result. ↩
-
My intent in writing this is to finally integrate the key things I learned in the last month. I suspect some of this is incorrectly interpreted by me; this also means I may have poorly vibe-coded RalPhD. ↩
-
This realisation might have been due to something Jeff said in a podcast or presentation; but searchability is a problem with inaccurately transcribed oral culture. ↩
-
Software engineers (SWEs) employ the word call instead of use; I am no SWE so I will use the words interchangeably as, to me, they don’t lose much meaning. ↩
-
Note that both agents can also write
checkpointfiles, like any subagent in this RalPhD setup if their context windows are reaching the pre-defined threshold value ↩ -
A practical example to understand this idea is that when you use Grok on Twitter; it does not use tools to build you stuff (yet). In contrast, Claude and ChatGPT can be invoked in Cursor, Claude Code, or Codex to build you cool things. This is my understanding so you can shoot the messenger if he’s wrong (i.e., shoot me, not Huntley). ↩
-
Admittedly, this last bit is doing a lot of heavy lifting but I will also add that LLMs can also be leveraged to engineer learning systems for non-experts to become experts. Whether any of us are reflective or patient enough to build these is up for debate. ↩
-
The more time I spend with Claude Code, the more I sense that the current model of academic research funding will be shaken up as will what counts as meaningful outputs. I am unsure exactly how this will happen but it feels inevitable that an AI-augmented researcher can operate with 100x-1000x lesser funding/resources in many scenarios to produce the same quality/quantity of outputs in a more compressed time-span. Also, much of what I have been proposing is possibly just not ambitious enough. ↩